Comment fonctionne ChatGPT ? Architecture, entraînement, limitations, bonnes pratiques
Introduction
ChatGPT est devenu en quelques mois le visage public de l’intelligence artificielle grand public. Développé par OpenAI, ce modèle de langage conversationnel a révolutionné notre rapport à la machine, passant d’un outil de recherche à un interlocuteur capable de rédiger, coder, expliquer et créer. Mais derrière cette interface simple se cache une architecture technique complexe, fruit de décennies de recherche en deep learning. Dans ce guide evergreen, nous décortiquons pièce par pièce le fonctionnement de ChatGPT : de l’architecture Transformer à l’entraînement par renforcement, en passant par ses limites et les bonnes pratiques pour en tirer le meilleur.
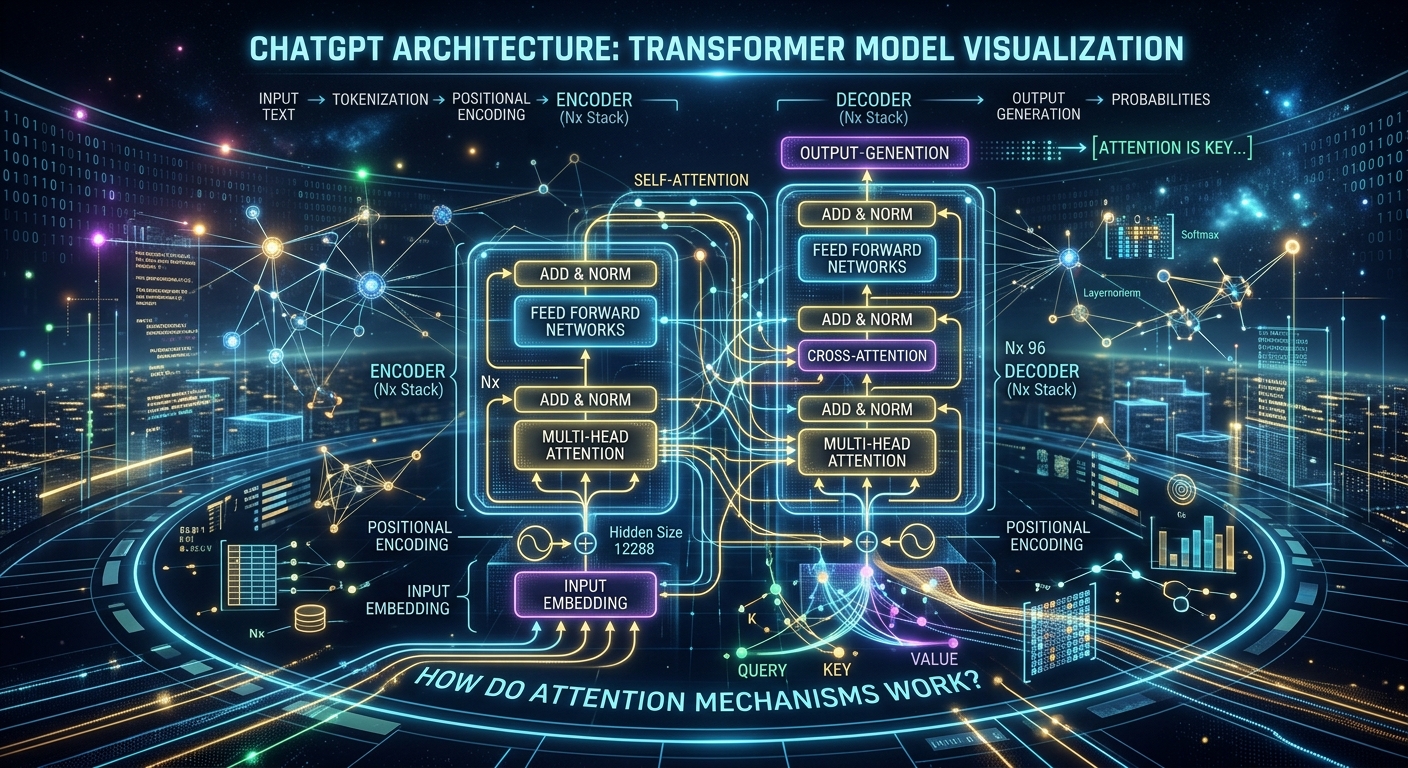
Architecture technique : le Transformer, cœur de l’intelligence

ChatGPT repose sur l’architecture Transformer, introduite par Google en 2017 dans le papier « Attention Is All You Need ». Cette architecture a remplacé les réseaux de neurones récurrents (RNN) et les LSTM, permettant un parallélisme massif et une modélisation de contexte à longue portée.
Les tokens : la langue que comprend l’IA
Avant d’être traité, le texte est découpé en tokens – des morceaux de mots, de syllabes ou de caractères. Par exemple, « ChatGPT » pourrait être tokenisé en « Chat » + « G » + « PT ». Cette tokenisation permet au modèle de gérer un vocabulaire étendu (environ 100 000 tokens pour GPT-4) tout en conservant une représentation compacte.
Le mécanisme d’attention : comprendre les relations
Le mécanisme d’attention permet au modèle de « regarder » les tokens précédents pour prédire le suivant. Contrairement aux RNN qui traitent les mots séquentiellement, l’attention calcule des scores entre chaque paire de tokens, capturant des dépendances à longue distance. Cela explique pourquoi ChatGPT peut maintenir une cohérence sur plusieurs paragraphes.
Les couches feed-forward et la normalisation
Chaque bloc Transformer contient aussi des couches feed-forward (réseaux de neurones classiques) et des opérations de normalisation qui stabilisent l’apprentissage. Empilés les uns sur les autres (jusqu’à 96 couches pour GPT-4), ces blocs forment un réseau profond capable d’abstractions de plus en plus complexes.
Entraînement : pré‑training, fine‑tuning et RLHF

L’entraînement de ChatGPT se déroule en trois étapes distinctes, chacune cruciale pour ses performances.
1. Pré‑training sur des milliards de textes
OpenAI alimente le modèle avec des quantités astronomiques de texte provenant d’Internet, de livres, d’articles scientifiques, etc. L’objectif : prédire le token suivant dans une séquence. Cette phase, purement auto‑supervisée, dure plusieurs semaines sur des clusters de milliers de GPU et coûte des millions de dollars. Elle forge la « connaissance » générale du modèle.
2. Fine‑tuning supervisé
Ensuite, des annotateurs humains rédigent des conversations idéales (prompt + réponse). Le modèle est affiné sur ce jeu de données pour aligner ses réponses sur un style conversationnel utile et inoffensif. Cette étape réduit les dérives et améliore la cohérence.
3. Reinforcement Learning from Human Feedback (RLHF) [paper]
C’est la clé du comportement « aligné » de ChatGPT. Des annotateurs classent plusieurs réponses du modèle par préférence. Un modèle de récompense (reward model) est entraîné pour noter la qualité des réponses. Puis, via un algorithme d’apprentissage par renforcement (PPO), ChatGPT apprend à maximiser cette récompense, ajustant finement ses paramètres pour produire des réponses jugées satisfaisantes par les humains.
Comment ChatGPT génère du texte : sampling, température, top‑p
Une fois entraîné, le modèle génère du texte token par token. À chaque étape, il calcule une distribution de probabilité sur l’ensemble du vocabulaire. Plusieurs techniques contrôlent la créativité et la cohérence :
– Sampling : choisir aléatoirement le token suivant selon les probabilités (par opposition au choix du token le plus probable, qui rendrait le texte monotone). – Température : paramètre qui aplatit (température > 1) ou accentue (température < 1) la distribution. Une température basse produit des réponses plus prévisibles, une température élevée introduit de la surprise. - Top‑p (nucleus sampling) : ne considérer que les tokens dont la probabilité cumulée dépasse un seuil (par exemple 0,9), éliminant les tokens trop improbables tout en gardant de la diversité.
Ces paramètres expliquent pourquoi ChatGPT peut tantôt donner une réponse factuelle standard, tantôt inventer une analogie créative.
Limitations connues : hallucinations, biais, connaissance coupée
Aussi impressionnant soit‑il, ChatGPT présente des faiblesses structurelles qu’il faut connaître pour l’utiliser à bon escient.
Hallucinations
Le modèle peut générer des informations factuellement fausses mais présentées avec une assurance trompeuse. Ce phénomène provient de l’apprentissage statistique : ChatGPT ne « sait » pas, il calcule des probabilités. Quand les données d’entraînement sont insuffisantes ou contradictoires, il invente.
Biais sociétaux
Les biais présents dans les textes d’entraînement (stéréotypes de genre, racialisation, vision occidentalo‑centrée) sont reproduits, voire amplifiés. OpenAI a déployé des filtres pour limiter les sorties offensantes, mais les biais subtils persistent.
Connaissance coupée
ChatGPT a une date de coupure (cut‑off) – par exemple septembre 2023 pour GPT‑4. Il ignore les événements postérieurs et les avancées techniques récentes, sauf si l’utilisateur les fournit dans la conversation.
Coût énergétique et environnemental
L’entraînement d’un grand modèle comme GPT‑4 consomme plusieurs gigawattheures, équivalant à l’émission de centaines de tonnes de CO₂. Son utilisation à grande échelle pose des questions de soutenabilité.
Bonnes pratiques pour utiliser ChatGPT efficacement
1. Soyez précis dans vos prompts
Un prompt vague donne une réponse vague. Précisez le format attendu (liste, tableau, paragraphe), le ton (professionnel, décontracté), le public cible, et la longueur.
2. Fournissez du contexte
ChatGPT n’a pas de mémoire à long terme entre les sessions. Répétez les éléments importants, ou utilisez la fonction « mémo système » (disponible dans l’API) pour guider le comportement du modèle.
3. Vérifiez les faits critiques
Ne prenez jamais une réponse technique, juridique ou médicale pour argent comptant. Recoupez avec des sources fiables, surtout pour des décisions importantes.
4. Jouez avec la température
Pour des tâches créatives (brainstorming, écriture fiction), augmentez la température (0,8‑1,2). Pour des réponses factuelles ou techniques, baissez‑la (0,2‑0,5).
5. Utilisez l’itération
Une première réponse peut être améliorée en demandant des précisions, en reformulant, ou en fournissant un exemple de sortie souhaitée. L’IA apprend de votre feedback immédiat.
6. Exploitez les capacités multimodales
Si vous avez accès à GPT‑4V ou à l’API de vision, envoyez des images, des schémas, des captures d’écran pour obtenir des analyses contextuelles.
7. Respectez les limites éthiques
Ne demandez pas à ChatGPT de générer du contenu trompeur, haineux, ou de contourner des sécurités. Non seulement c’est contraire aux conditions d’utilisation, mais cela risque de dégrader la qualité des réponses.
Notre avis
ChatGPT représente un saut quantique dans l’interaction homme‑machine, mais il ne faut pas y voir une intelligence générale. C’est un outil statistique extrêmement sophistiqué, capable de simuler la compréhension grâce à une masse de données inégalée. Son impact sur la productivité individuelle est déjà tangible – rédaction, débogage, synthèse – mais son utilisation à l’échelle sociétale pose des défis éthiques, environnementaux et économiques.
À court terme, ChatGPT et ses successeurs vont continuer de s’intégrer dans nos workflows, automatisant les tâches routinières et libérant du temps pour la créativité et la stratégie. À long terme, la question n’est pas « l’IA va‑t‑elle nous remplacer ? » mais « comment l’humain et l’IA peuvent‑ils collaborer pour résoudre des problèmes plus grands ? ». La clé est l’éducation : comprendre comment fonctionne cet outil pour en tirer le meilleur sans en devenir dépendant.
Sources :
OpenAI, « Introducing ChatGPT »
OpenAI, « GPT‑4 Technical Report »
Vaswani et al., « Attention Is All You Need »
Christiano et al., « Deep Reinforcement Learning from Human Preferences »
Bender et al., « On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? »
Liens internes
– Comment Rédiger des Prompts efficaces pour ChatGPT ? – Meilleures IA pour réviser en 2025 : Guide pour étudiants – Top 5 des Générateurs IA de Musique en 2025